
Over summer 2022, I interned at QCRI with the Crisis Computing team. I (Abhigyan Kishor) was assigned the task of developing a robust pipeline for downloading and processing satellite imagery for flood detection. I went on to develop a rather ingenious satellite imagery downloader using Google Earth Engine (GEE). This blog attempts to document the ideation and implementation that went into building the final version of the downloader.
A brief history of disaster mapping with satellite imagery
Satellite imagery has been around since the late 70s. However, only in recent years, with the advancement in computer technologies have we seen artificial intelligence (AI) used with geospatial data for improved inference. Satellite imagery along with AI finds a niche application in disaster management. The various teams at QCRI use satellite imagery for different purposes such as detecting buildings and their types (e.g. residential, industry), population density estimation, detection of damaged buildings after disasters, and poverty mapping. Our team specifically focuses on flood mapping using Optical and SAR satellite imagery.
The downloader: An introduction
The Crisis Computing team at QCRI is focused on developing a near real-time flood mapping system for disaster response and recovery. The project utilizes AI to detect flood-affected areas from open-source satellite imagery. As with any image processing project, the model training depends heavily on the availability of relevant training images to provide accurate results. Thus it was imperative that our project starts with a satellite imagery downloader. This tool would have to be customizable and have the ability to download open-source satellite imagery without any size limitations, and against complex areas of interest.
Why develop a downloader from scratch?
A simple google search around satellite imagery downloader will give you a multitude of imagery tools at your disposal. Some examples include sentinelsat, sentinelhub-py and geedim. At first glance, these seem to be much more proven and robust alternatives. However we decided to build the downloader from scratch with GEE as all other tools fell short of our requirements for the following reasons:
- Compatibility with requirements
The challenge with finding a downloader for this project was its list of unique requirements. In our case, we needed to be able to provide the downloader with a variety of input formats for the region of interest. None of the tools above support multiple types of polygons, or types of file formats i.e. WKT, Shapefile, GeoJSON, or coordinate reference systems altogether. Moreover, the flood detector required certain no-data values on the downloaded images for the algorithm to classify the pixels correctly. Finally, the script had to run within the strict confines of the QCRI servers, which while extremely capable, are used by different teams and often reach capacity on either the CPU or GPU. All things considered, I decided that instead of working around heavy, cumbersome and unknown tools, I should simply write my own image downloader to cater to these unique requirements.

2. Slower Local Tiling
What is tiling? Tiling is the process of converting the region of interest into a grid of smaller rectangles, which can be downloaded quicker individually because of their simple shape. Tiling the region of interest is crucial for working around the limited download size allowed by Google Earth Engine (32MB). Some of the tools mentioned above perform local tiling, i.e. tiling performed by the local computer.
Flood events are usually very localized, ranging from 100s – 100,000 sq km, depending on the perpetrator of the flood. Google Earth Engine, despite its strict memory limitations, provides built-in functionality to support flexible tiling over a region of interest. All calculations in the google earth engine are implemented with parallelism in mind and are extremely optimized. So naturally, I opted for using the geometry tools provided by GEE instead of reinventing the wheel. Thus by offloading our expensive calculations over to GEE, we save precious time in the preliminary stages of generating the tiles to be downloaded.
3. The limitations of multiprocessing in python
Global Interpreter Lock (GIL) is one of the quirks of python which prevents true parallelism. At some point in its infancy, the developers of python decided to implement a single mutex lock on all threads, which makes all threading libraries in python behave more like asynchronous code. As one can imagine, this makes multithreading very slow in python, especially in CPU-bound tasks such as image downloading. It is recommended to use multiprocessing as an alternative to speed up code and truly achieve some semblance of parallelism in python. None of the above tools use the multiprocessing libraries and therefore skimp on some of the speed benefits obtained.
Google Earth Engine: limitless data, limited downloads

Google Earth Engine combines a multi-petabyte catalog of satellite imagery and geospatial datasets with planetary-scale analysis capabilities. Scientists, researchers, and developers use Earth Engine to detect changes, map trends, and quantify differences on the Earth’s surface.
While deciding to create a downloader, we had the option of choosing different service providers for satellite imagery. We chose GEE because of its simple and intuitive graphical interface which allowed us to visualize our products and its robust python API which provided powerful tools for processing satellite imagery before its download. GEE also provided different computed datasets from the satellite imagery in a standardized manner, which were very useful for supplementing our solution for flood mapping.
However, GEE does not allow for big downloads of satellite imagery locally. The getDownloadURL() function allows for a maximum of 32MB download. If larger downloads are required, one has to resort to batch downloading which downloads images to a cloud bucket. Further, queuing of tasks for the batch process takes upwards of 10 minutes before the download may begin. Integrating this into a pipeline that focuses on speed and availability is simply not practical.
Further, GEE is built upon the google cloud platform. So the number of concurrent requests to the GEE catalog by the compute engine are limited by the same quotas of google cloud. Heavy calculations are memory limited and often require multiple retries implemented client side to achieve them.
All these problems aside, over the course of this internship, I came to think of a more novel approach using GEE with its python API. Heavily inspired by Noel Gorelick’s article, I set out to see if any, if not all of these problems could be solved. And it turns out, I ended up doing just that.
The Pros of downloader.py
- The lack of dependencies
Arguably the most valuable benefit is its ease of use and modifiability. Offloading heavier calculations over to GEE makes this script surprisingly lightweight, using, at its core only 3 external libraries (gee, gdal and retry). This makes for a dependency free and simple development of tools around the core script.
As I have mentioned, I was tasked with integrating the downloader into a pipeline to feed into the flood detector. The front end to be presented to the end users was created in ArcGIS Pro, which has a strict dependency on Python 3.7. Further, we used a REDIS server to allow for buffering between different states of the user experience, i.e. selecting a region of interest, sending the request to the downloader, and reflecting the result of the download to the user. As a result, this puts an environment constraint on the downloader. However, the lack of dependencies allowed the downloader to be integrated fairly smoothly into the environment. Further, the flood detector required replacing the no-data values in the final image with NAN values. Again, because of the flexibility of the script, we were able to quickly sort out the issues.
2. Use of multiprocessing library
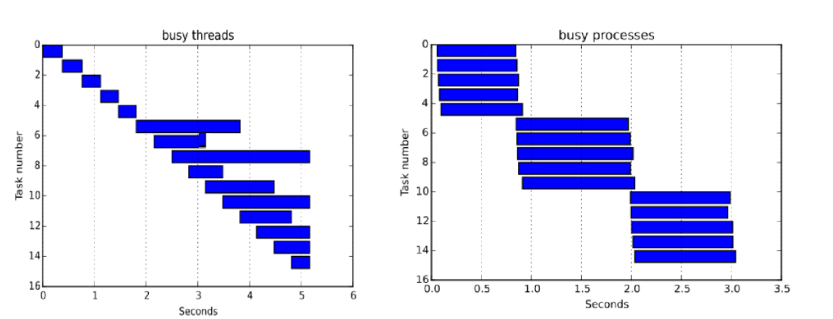
One of the major contributors to speed is the use of the multiprocessing library in python. While it shares most of the core API functions of the multithreading library, it allows us to bypass the GIL in python, which makes the downloads much faster. Care must be taken not to over-provision the processes, as this can lead to large requests to the compute engine subsequently resulting in rate blocking. The multiprocessing library pairs well with the use of the SharedMemoryManager library which allows us to store the shapes of the tiles in shared memory to reduce the memory footprint of the overall program. However, SharedMemoryManager was only introduced in python 3.8 so this may result in some dependency clashes. I will provide rough examples to illustrate various ways of using the multiprocessing library.
i) Multiprocessing.Pool
This method simply provisions the processes and provides an interface to the multiprocessing library to provide objects to be run against a function. It provides little control over the execution of the processes and results in deadlocks in less powerful architectures. Chunksize, an optional argument of starmap in conjunction with the maxtasksperchild argument of the Pool can be used to increase the efficiency of this code.
With Multiprocessing.Pool(25,<maxtasksperchild>) as Pool:
Pool.starmap(<download_tile()>, <args>, <chunksize>)ii) concurrent.futures.ProcessPoolExecutor
The concurrent.futures library allows users significantly more control over the execution of the process by providing users with a futures object. This object has many built-in functions which allow control of execution and recycling of threads in a safe manner. As mentioned in the documentation: “concurrent.futures.ProcessPoolExecutor offers a higher level interface to push tasks to a background process without blocking execution of the calling process. Compared to using the Pool interface directly, the concurrent.futures API more readily allows the submission of work to the underlying process pool to be separated from waiting for the results.”
The futures object also provides us with callbacks. The add_done_callback is one such example which can be used to implement simple progress bars and improve the experience of the download. The ProcessPoolExecutor does result in as many deadlocks as the Multiprocessing.Pool.
with concurrent.futures.ProcessPoolExecutor(max_workers = workers) as pool:
futures = [pool.submit(<download_tile()>, <args>)]
for future in futures:
future.add_done_callback(<update_progress_bar>)iii) SharedMemoryManager in conjunction with ProcessPoolExecutor
As the number of tiles to be downloaded increases, the ProcessPoolExecutor slows down. This is because each process must have its own copy of the shape of the tiles, as processes, unlike threads, don’t share the same memory space. However, with the introduction of SharedMemory, we can simply create the tiles in a shared context so that they are visible to all the processes. As a result, there is only one copy of the tiles, and the memory footprint of the program is significantly reduced. SharedMemoryManager is used as a context manager for the memory to allocate and deallocate it correctly. Further, we use numpy arrays because they easily provide methods to find the bytes and reconstruct the arrays back from the byte state of the memory.
with SharedMemoryManager() as smm:
shm = smm.SharedMemory(np_array.nbytes)
shared_np_array = np.ndarray(np_array.shape, np_array.dtype, buffer=shm.buf)
shared_np_array[:] = np_array[:]
with concurrent.futures.ProcessPoolExecutor(max_workers = workers) as pool:
futures = [pool.submit(<function>, <args>)]
for future in futures:
future.add_done_callback(<update_progress_bar>)
3. Region of interest simplification
The single greatest contributor to speed by far is the simplification of complex geometries passed to the tile downloader section. GEE struggles with complex joins of different geometries which often leads to a snowballing slow down on the rest of the downloader. So instead of complex regions, I pass simplified regions to the downloading script. Later, using gdal, we clip the downloaded image to the original region of interest.
Some regions like islands can have complex geometries such that their vertices are very high, and this can slow down the downloading significantly. To overcome this challenge, we created a convex hull over the region, which is a minimum bounding geometry of the area of interest, and used this to download satellite imagery. The imagery is then clipped to the original area of interest to produce the final result. To demonstrate this, the case study of Central Abaco, Bahamas is taken which originally has 30,213 number of vertices.
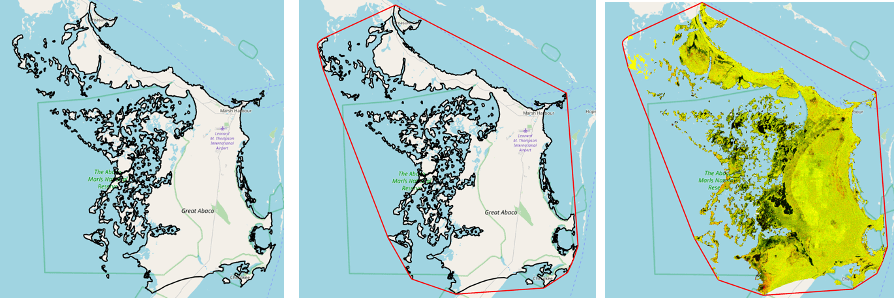
Without convex hull → 2.9 minutes
With convex hull→ 48 seconds
Downloader time improved by ~2 minutes
4. Relevant tiling for large areas (the giga_tiler)
For larger regions, I improve the focus of the downloader by finding tiles in the areas where satellite imagery is present. Check out this blog post where I discuss this in detail. This greatly speeds up the downloading time.
Instead of creating tiles over the AOI, tiles are created over the satellite imagery swath and the tiles are downloaded. To demonstrate this, South Sudan is taken as a use case where we will be downloading Sentinel-2 imagery for 20st February 2019. The satellite imagery found in this region covers the center of South Sudan with an area coverage of ~35% as seen below.
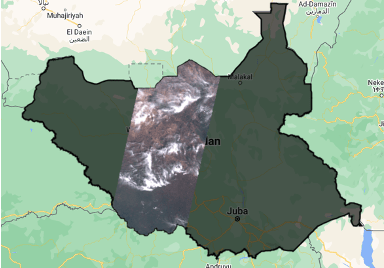
The regular tiling algorithm creates 8832 tiles over the whole region of interest. But with focused tiling, we only create 2252 tiles over the whole swath.

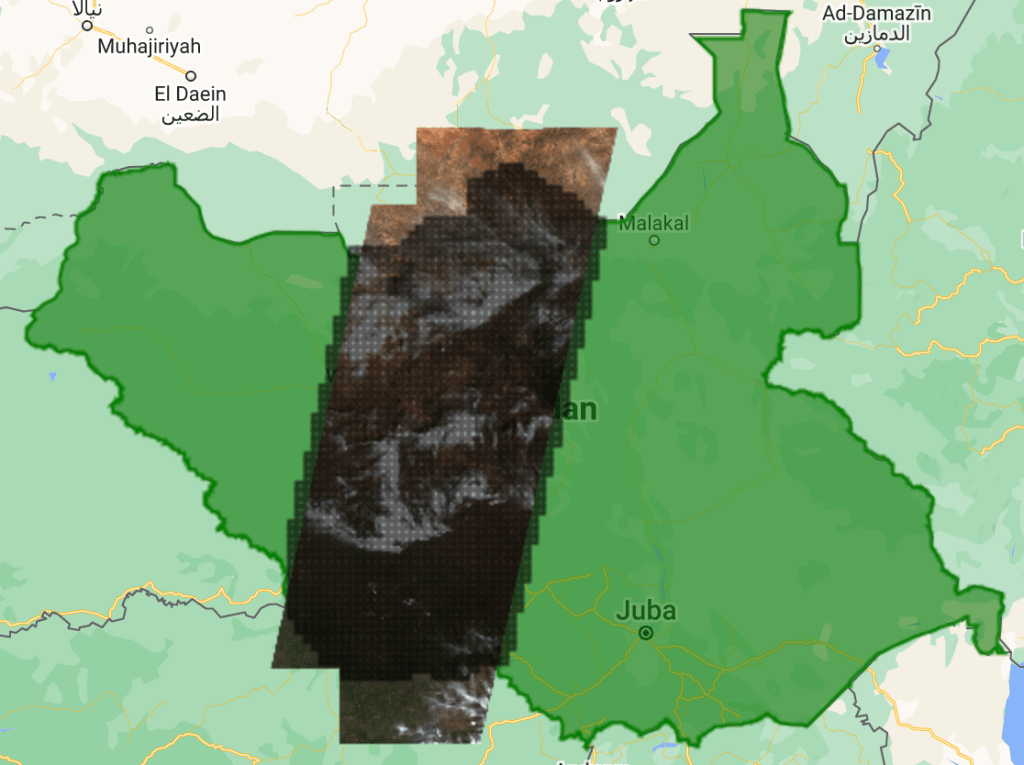
Without gigatiler (left)→ 25.5 minutes
With gigatiler (right) → 15.5 minutes
Downloader time improved by ~10 minutes
5. Selective use of retries
With most GIS APIs, use of retries are quite common as APIs are prone to getting overwhelmed with memory calculations and multiple requests. GEE is no different. GEE works with a client-side and server-side interface. The aim of a good script is to try and maximize the server-side interaction and minimize the client-side interaction. This allows the most efficient use of google clouds’ compute engine. In our script, as I have mentioned, we query GEE for the tiling and the imagery. Both of these queries have been encapsulated in exponential backoff style retries to ensure that the client-side receives the calculations even in case of slight memory overload.
The retry library in python comes with a decorator which allows us to easily turn any function into a retry implemented one as shown:
@retry(tries=2,delay=1,backoff=2)
def function(<args>):
passRoom for Improvement
Of course, as with most good things, my time at QCRI came to an end. Plenty of room for improvement in our downloader such as:
- Recursive tiling with the best effort
As GEEs greatest drawback is the download size limit, recursive tiling is required to predict the best size of tiles from download. Geedim uses local tiling and estimation to predict the largest possible tile to safely try and download. I would like to implement a best-effort approach to estimating tile size using GEE. However, download size is not known until download and that’s where some intelligent use of data types and their corresponding sizes may come in handy. Couple it with a count-every reducer and perhaps we may have a very good estimate of the download size.

Conclusion
GEE has allowed us to make a powerful satellite imagery downloader of any dataset in the GEE catalog, be it Sentinel-1 and Sentinel-2. Since the downloaded imagery gets passed to its relevant flood detector, which is either a SAR model or an Optical model, the next article in this series will cover the implementation of both these flood detectors.
